[Data Structure] 트라이(trie)
트라이(Trie)에 대한 개념을 알아보고 코드로 구현해보자

◾ 트라이(Trie)
트라이(Trie)는 문자열 집합을 효율적으로 저장하고 탐색하기 위해 설계된 트리 형태의 자료구조다. 트리(Tree)와 탐색(Retrieval)이라는 단어에서 유래되었으며, 주로 사전 찾기, 검색어 자동완성 등에 활용되고, ‘접두어’를 찾아야 하는 알고리즘 문제에서 자주 쓰인다.
◾ ‘트라이’를 사용하는 이유
굳이 새로운 자료구조를 배워야할까? 그냥 우리가 잘 알고있는 배열이나 리스트에 단어를 저장하고 필요할 때 검색해서 찾아도 충분하지 않을까?
결론부터 말하자면 굳이 트라이를 사용하는 이유는 시간복잡도 측면에서 압도적으로 빠르기 때문이다.
배열(리스트)을 이용한 검색의 한계
만약 배열(리스트)에 100만 개의 단어가 들어있고, 여기서 algorithm 이라는 단어를 찾는다고 해보자.
1
2
3
4
5
6
7
8
9
10
String[] words // 100만개의 단어가 들어있는 배열
for (String word : words) {
if (word.equals("algorithm")) {
System.out.println("algorithm 이라는 단어를 찾았습니다.");
return;
}
}
System.out.println("algorithm 이라는 단어를 찾지 못했습니다.");
일일이 반복문을 통해 배열(리스트)을 순회하면서 해당 단어가 algorithm 과 일치하는 지 확인을 해야한다. 또한 자바의 String.equals() 메서드는 문자열의 각 문자를 처음부터 순차적으로 비교한다.
따라서 전체 단어의 개수를 $N$, 단어의 최대길이를 $L$ 이라고 할 때, 시간복잡도는 $O(N×L)$ 이 된다. 위 예시에서 단어의 최대길이가 10이라면
최악의 경우 100만 × 10 = 1,000만 번의 연산을 하게되는 것이다.
하지만, 트라이 자료구조를 이용한다면 단어검색의 시간복잡도는 $O(L)$로, 획기적으로 줄어든다. 단어가 100만개가 있든, 1000만개가 있든
algorithm 이라는 단어를 단 9번 만의 연산으로 존재여부를 확인할 수 있는 것이다.
어떻게 이게 가능한지 트라이 구조를 한 번 살펴보자.
그 전에…
굳이 트라이를 사용해야될까? Set 자료구조에 단어를 저장하고, 검색할 때는 set.contains(”algorithm”) 으로 검색하면 $O(1)$ 만에 찾을 수 있지 않나?
→ 맞다. set.contains() 메서드를 사용하면 매우 빠르게 해당 단어의 유무를 확인할 수 있다. (정확히는 트라이와 마찬가지로 $O(L)$)
단순 단어의 존재 유무만 확인한다면 굳이 트라이를 쓸 필요 없이 Set을 활용하면 된다.
하지만 트라이는 Set과 달리 부분 검색(Prefix Search)이 가능하다. Set은 algorithm처럼 하나의 저장된 단어는 찾을 수 있지만 특정 문자열로 시작하는 단어는 한 번에 찾을 수 없다.
예를들어, 단어들 중에 al- 로 시작하는 단어를 찾고싶을 때, Set에서는 일반 배열(리스트)과 마찬가지로 전부 순회해서 해당 단어가 al- 로 시작하는 지 확인해야한다. $O(n)$
이러한 상황에서 트라이 자료구조가 빛을 발한다. 트라이는 전체 문자열 검색과 마찬가지로 부분 검색을 할 때도 $O(L)$ 의 시간복잡도로 가능하다. 어떻게 이게 가능한지 이제 진짜 알아보자.
◾ 트라이의 구조
트라이는 단어를 한 글자씩 쪼개서 노드로 만들어서 트리 형태로 저장한다. 트리의 가장 꼭대기에는 비어있는 루트(Root) 노드가 자리하며, 이곳이 모든 탐색과 삽입의 출발점(헤더) 역할을 하게 된다.
단어 삽입
이제 “algorithm” 이라는 단어를 저장해보자.
- 루트노드에서 출발 : 삽입을 시작할 때는 항상 루트 노드에서 출발한다.
- 한 글자씩 자식노드로 연결 : 먼저 첫 문자인
a를 루트의 자식 노드로 생성한다. 이어서 다음 문자인l을a의 자식으로, 그 다음 문자인g를l의 자식 노드로 연결해나간다. - 단어의 끝 표시 :
a→l→g→o→ …. 순서로 노드를 생성하며 내려간다. 마침내 마지막 글자인m을 저장한 뒤, 해당 노드가 단어의 마지막 글자임을 표시한다.(isEndOfWord = true)
algorithm 삽입을 완료한 트라이의 모습이다.

추가적으로 aluminum, app, apple, banana, car 을 삽입한 후의 모습이다.
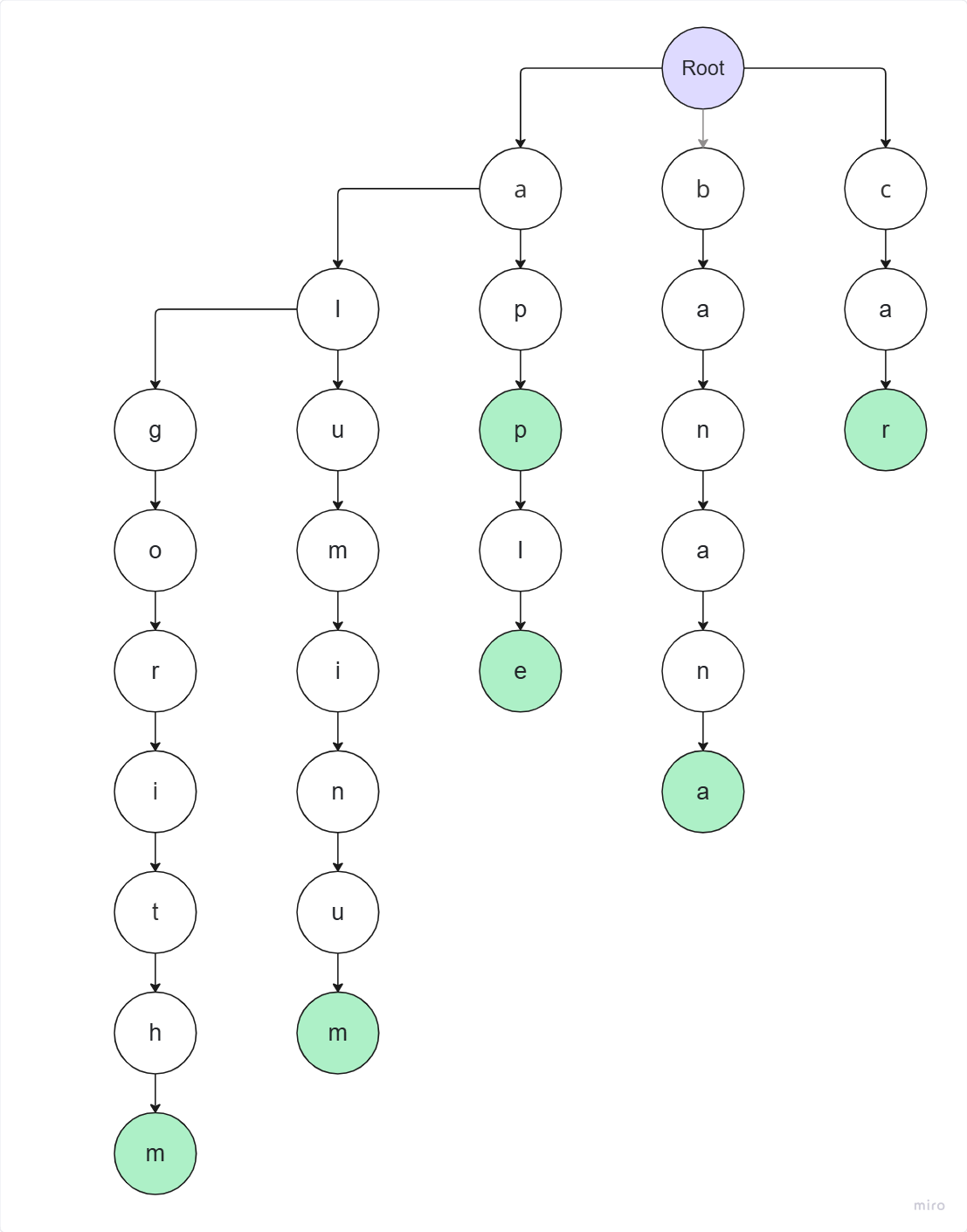
단어 검색
이제 “algorithm” 이라는 단어를 검색해보자. 검색도 삽입 과정과 매우 유사하다.
- 루트 노드에서 출발 : 검색을 시작할 때도 항상 트리의 최상단인 루트 노드에서 출발한다.
한 글자씩 자식 노드로 이동 : 찾고자 하는 단어의 첫 문자부터 순서대로 자식 노드를 따라 내려간다.
a→l→g→o→ …. 순서로 이동한다.
만약 중간에 다음 문자로 이어지는 노드가 없다면, 길이 끊긴 것이므로 탐색을 즉시 중단하고 해당 단어가 없다고 판단한다.(예:
g다음에o노드가 없는 경우)단어의 끝 표시 확인 : 단어의 마지막 글자인
m까지 무사히 도달했다면, 마지막으로 해당 노드에 ‘단어의 끝(isEndOfWord)’ 표시가 되어 있는지 확인한다. 표시가 되어 있다면 검색 성공이다.표시가 되어있지 않다면, 이는 다른 단어의 접두사로 쓰이고 있을 뿐 독립적인 단어가 아니므로 검색 실패로 처리한다.
(예:
algo라는 단어를 검색했을 때, 마지막 글자인o에는isEndOfWord가 표시되어있지 않으므로, 검색 실패처리가 된다.)
(algo는algorithm의 접두사로서만 존재)
삽입/탐색 시뮬레이션
아래에서 트라이 자료구조에서 삽입, 탐색 시 어떻게 동작하는 지 확인할 수 있다. 직접 문자열을 넣어보고 검색해보자.
◾ 자바코드 구현
트라이 자료구조를 코드로 구현해보자.
TrieNode
트라이를 구성하는 기본단위인 TrieNode 클래스
1
2
3
4
5
6
7
8
9
10
11
12
class TrieNode {
// 알파벳 소문자 26개를 저장할 수 있는 배열('a' ~ 'z')
TrieNode[] children;
// 단어의 끝(완성된 단어)인지 여부를 표시
boolean isEndOfWord;
public TrieNode() {
children = new TrieNode[26];
isEndOfWord = false;
}
}
알파벳 소문자만 다룬다는 가정 하에 26크기의 배열로 설정했다.
열의 각 칸(인덱스)은 특정 알파벳으로 향하는 길을 의미한다.
children[0]→a로 가는 길children[1]→b로 가는 길children[2]→c로 가는 길- …
children[3]→z로 가는 길
만약 대소문자, 숫자, 특수문자 등을 모두 담을 수 있는 트라이를 만들고 싶다면 배열이 아닌, Map을 사용하면 된다.
1
Map<Character, TrieNode> children = new HashMap<>();
Trie
삽입, 검색 기능이 있는 Trie 클래스
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
public class Trie {
private TrieNode root; // 헤더 역할을 하는 루트 노드
public Trie() {
root = new TrieNode(); // 트라이 생성 시 비어있는 루트 노드를 초기화
}
// [단어 삽입]
public void insert(String word) {
TrieNode current = root;
for (int i = 0; i < word.length(); i++) {
char ch = word.charAt(i);
// 'a'를 빼서 0~25 사이의 인덱스로 변환 (예: 'a'-'a'= 0, 'b'-'a'=1)
int index = ch - 'a';
// 해당 문자로 가는 길이 없다면 새로운 노드 생성
if (current.children[index] == null) {
current.children[index] = new TrieNode();
}
// 다음 노드로 이동
current = current.children[index];
}
// 단어의 모든 문자를 넣은 후, 마지막 노드에 끝임을 표시
current.isEndOfWord = true;
}
// [단어 검색]
public boolean search(String word) {
TrieNode current = root;
for (int i = 0; i < word.length(); i++) {
int index = word.charAt(i) - 'a';
// 중간에 길이 끊겼다면 단어가 없는 것
if (current.children[index] == null) {
return false;
}
current = current.children[index];
}
// 길은 끊기지 않았지만, 누군가의 접두사일 수 있으므로 isEndOfWord 반환
// false 를 반환하면 단어가 아닌 접두사임을 의미함
return current.isEndOfWord;
}
}
*추가 - startsWith() 메서드
해당 문자열로 시작하는 단어가 있는 지 확인하는, 접두사 검색 메서드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public boolean startsWith(String prefix) {
TrieNode current = root;
for (int i = 0; i < prefix.length(); i++) {
int index = prefix.charAt(i) - 'a';
// 접두사 자체가 트리에서 끊긴다면 없는 것
if (current.children[index] == null) {
return false;
}
current = current.children[index];
}
// 중간에 끊기지 않고 무사히 도달했다면, 그 뒤로 단어가 더 있든 여기서 끝나든 접두사로는 존재하는 것!
return true;
}
◾ 마무리
시간복잡도와 공간복잡도는 trade-off 관계이다. 트라이 자료구조는 속도가 매우 빠르지만 문자 하나하나를 노드로 관리하기 때문에 메모리를 많이 잡아먹는다.
목적에 맞게 잘 사용하자.
(단순히 단어의 존재유무만 확인한다면 HashSet 이 더 낫다.)
트라이 자료구조를 연습할 수 있는 문제
댓글 0