[백준] 14426. 접두사 찾기 (Java)
[백준] 14426. 접두사 찾기 풀이

◾ 문제
총 $N$개의 문자열로 이루어진 집합 $S$가 주어졌을 때, 이어지는 $M$개의 문자열 중에서 적어도 하나의 집합 $S$에 포함되어 있는 문자열의
접두사(Prefix)인 것의 개수를 구하는 문제다.
◾ 알고리즘 [접근 방식]
단순 이중 반복문을 통한 검사?
이 문제를 처음 접했을 때 가장 먼저 떠올릴 수 있는 방법은 이중 반복문을 이용해 $M$개의 문자열을 $N$개의 문자열과 일일이 대조해 보는 것이다. 하지만 항상 제한 시간과 시간 복잡도를 먼저 고려해야 한다.
$N$과 $M$은 각각 최대 $10,000$이고, 주어지는 문자열의 최대 길이 $L$은 $500$이다.
만약 자바의 String.startsWith()를 이용해 매번 처음부터 탐색한다면, 최악의 경우 시간 복잡도는 무려 $O(N \times M \times L)$이 된다. 이를 계산해 보면 $10,000 \times 10,000 \times 500 = 50,000,000,000$ (500억) 번의 연산이 발생하므로, 제한 시간 내에 통과할 수 없다.
트라이(Trie)
이 문제처럼 접두사를 찾아야 하거나 문자열을 검색해야 할 때 정석적으로 사용되는 자료구조가 있는데, 그게 바로 트라이(Trie)다.
트라이에 대한 자세한 설명은 아래 포스팅 참고
핵심 로직
- 집합 $S$에 속하는 $N$개의 문자열을 트라이에 삽입한다. $O(N \times L)$
- $M$개의 문자열을 입력받을 때마다 해당 문자열이 트라이 구조를 따라갈 수 있는지 탐색한다. $O(N \times L)$
- 탐색 도중 가리키는 노드가
null이 되면 접두사가 아니며, 끝까지 무사히 도달했다면 접두사로 판별하고 카운트를 증가시킨다.
이러면 총 시간 복잡도는 $O((N + M) \times L)$로 단축되어 최악의 경우라도 $1,000$만 번만 연산이 발생하므로 여유롭게 통과할 수 있다.
현재, 집합 S에 해당하는 startlink, codeplus, sundaycoding, codingsh가 트라이에 삽입되어있다.
(baekjoononlinejudge 는 너무 길어서 뺐다..)
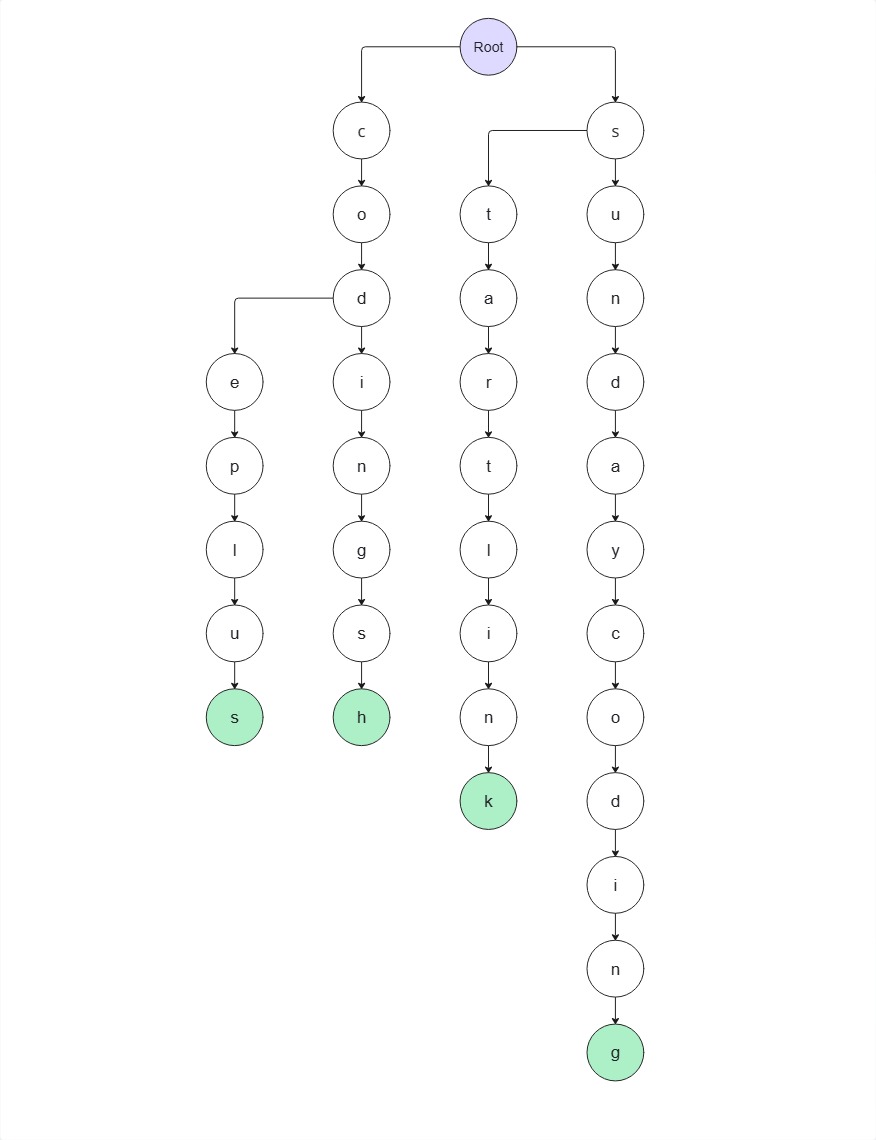
star 라는 문자열이 입력으로 들어왔을 때, 집합 S에 포함되는 문자열들 중 적어도 하나의 접두사인 지 체크해보자.
1. s 노드가 존재하므로 해당 노드로 이동
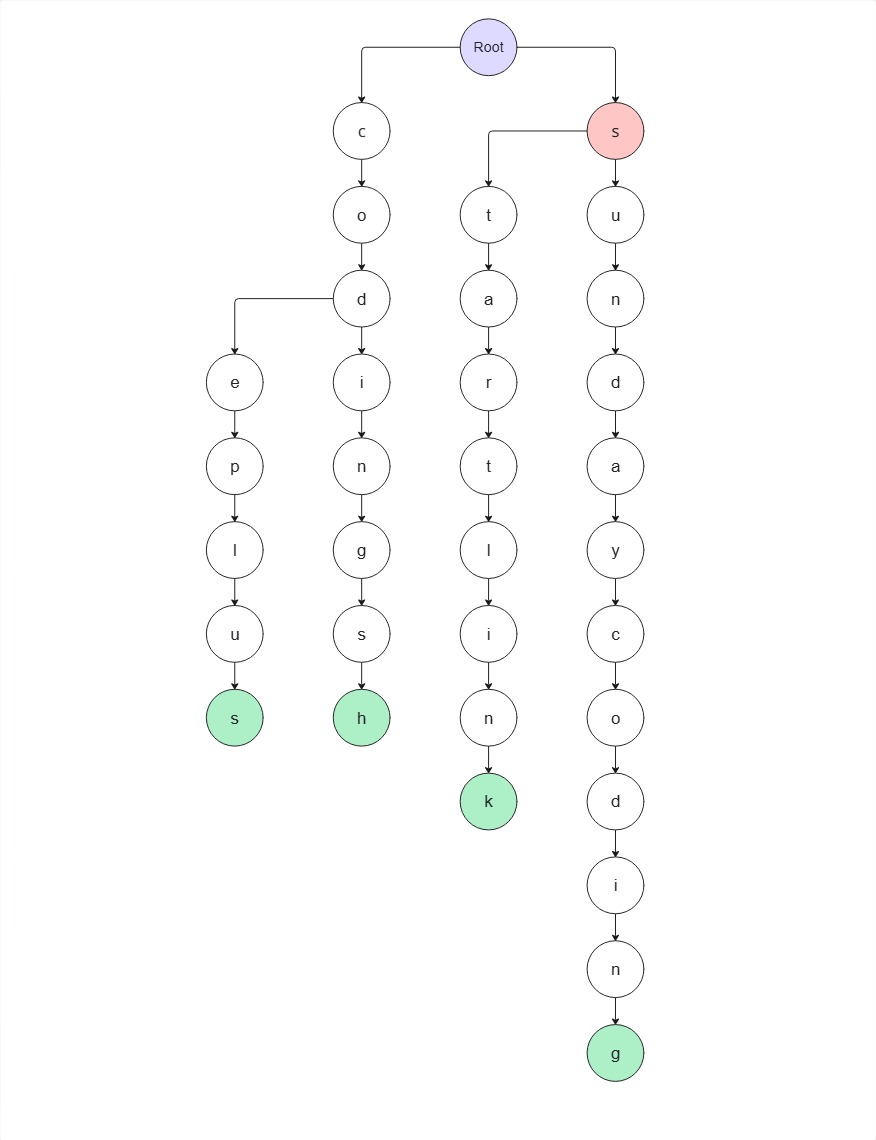
2. s → t 노드가 존재하므로 이동
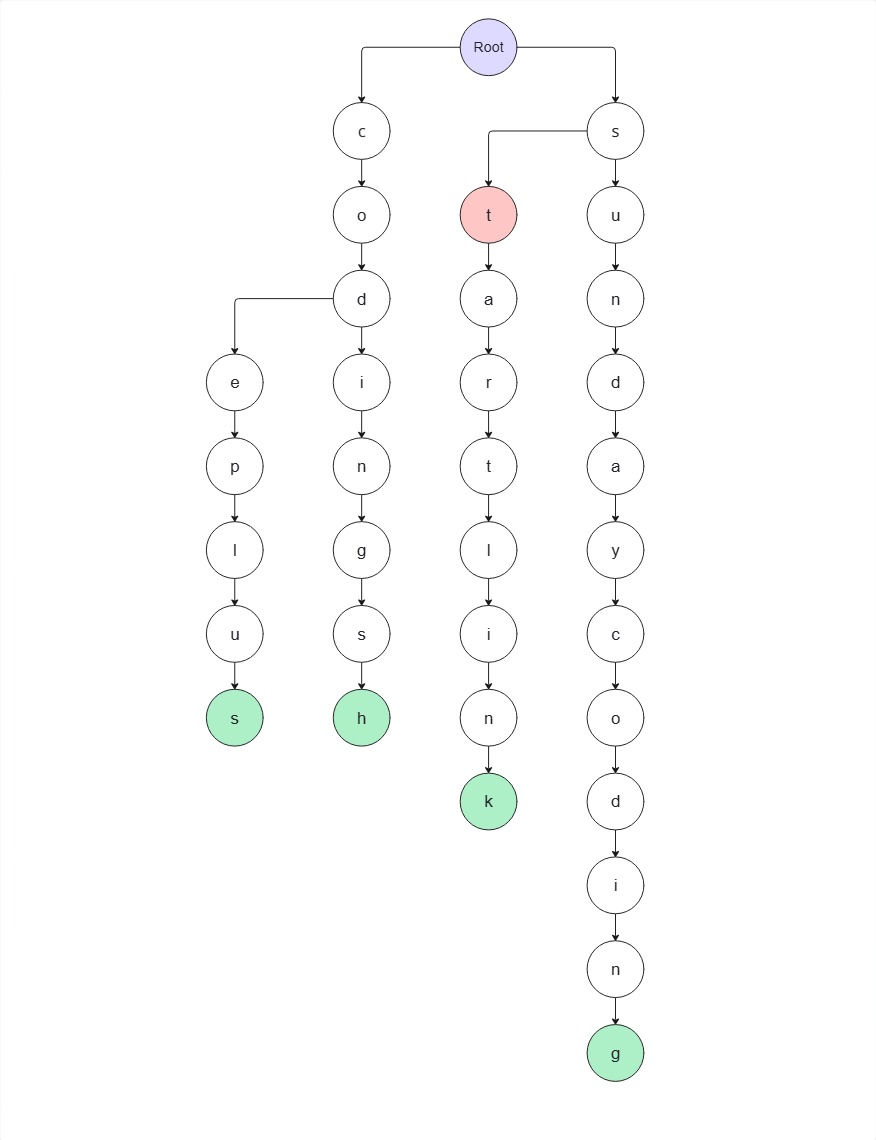
3. t → a 노드가 존재하므로 이동
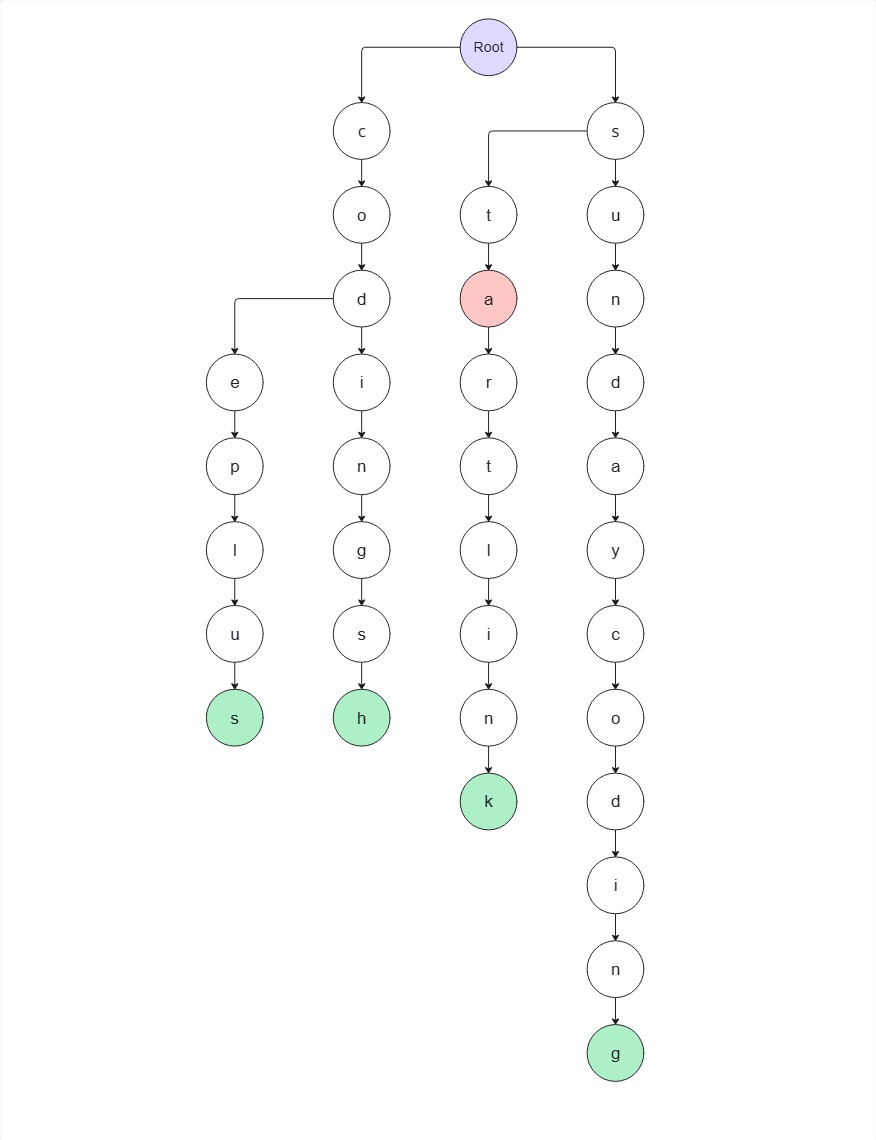
4. a → r 노드가 존재하므로 이동
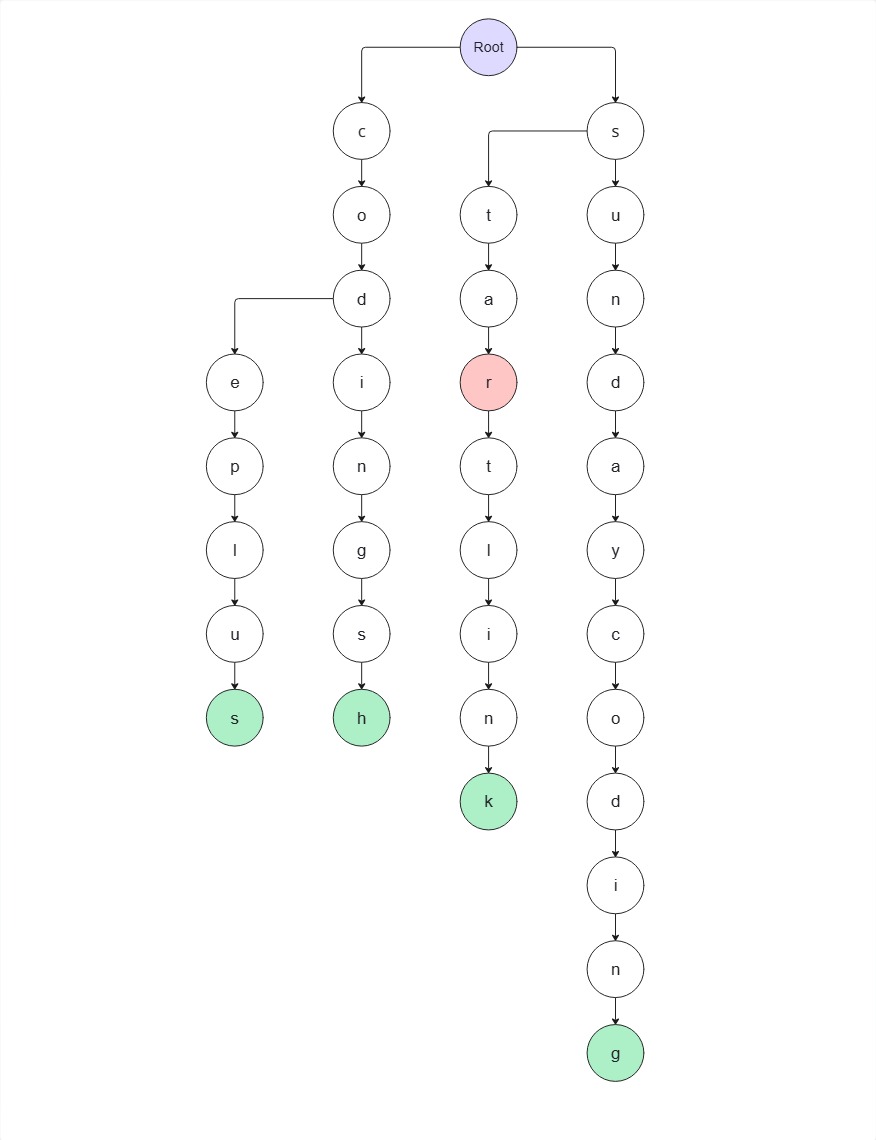
s → t → a → r 까지 끊기지 않고 무사히 이동했으므로 문자열 star 는 집합 S에 포함된 문자열 중 하나의 접두사이다. (starlink의 접두사)
이번엔 plus 가 접두사가 되는 지 체크해보자
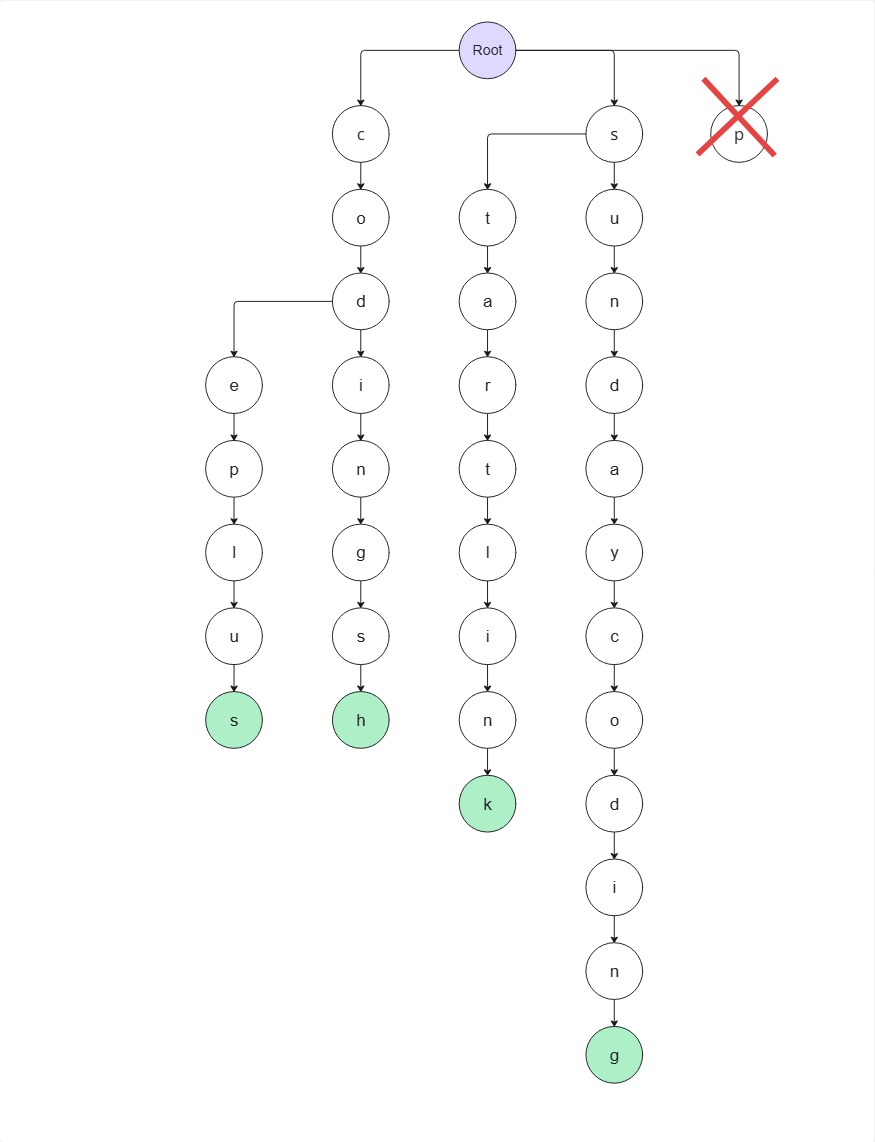
Root → p 로 이동할 수 있는 노드가 존재하지 않기 때문에 문자열 plus 는 접두사가 아니다.
◾ 코드
TrieNode
트라이에서는 각 문자를 노드로서 관리하기 때문에 TrieNode 클래스를 만들어준다.
1
2
3
4
static class TrieNode {
// 알파벳 소문자(26개)를 저장할 자식 노드 배열
TrieNode[] children = new TrieNode[26];
}
이 문제는 알파벳 소문자만 다루므로, 배열의 크기를 26으로 설정한다. 배열의 각 칸(인덱스)은 특정 알파벳으로 향하는 길을 의미한다.
children[0]→a로 가는 길children[1]→b로 가는 길children[2]→c로 가는 길- …
children[25]→z로 가는 길
이 문제에서는 단순히 ‘접두사’인지만 확인하면 되므로, 트라이 구현시 기본적으로 존재하는 isEndOfWord 플래그를 이번엔 생략해도 무방하다.
Trie
TrieNode들을 이용해 단어를 등록(insert)하고, 접두사가 될 수 있는지 검색(startsWith)을 하는 클래스다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
static class Trie {
// 모든 단어의 출발점. 첫 글자로 가기 위한 헤더 역할을 한다.
TrieNode root = new TrieNode();
// 1. 단어 삽입
public void insert(String word) {
TrieNode node = root;
for (int i = 0; i < word.length(); i++) {
// 해당 문자의 인덱스 ex) a = 0, z = 25
int index = word.charAt(i) - 'a';
// 자식 노드가 없다면 새로 생성
if (node.children[index] == null) {
node.children[index] = new TrieNode();
}
// 다음 노드로 이동
node = node.children[index];
}
}
// 2. 접두사 탐색 (startsWith)
public boolean startsWith(String prefix) {
TrieNode node = root;
for (int i = 0; i < prefix.length(); i++) {
int index = prefix.charAt(i) - 'a';
// 접두사의 글자를 따라가다가 길이 끊기면 접두사가 아님
if (node.children[index] == null) {
return false;
}
node = node.children[index];
}
// 무사히 끝까지 도달했다면 접두사가 맞음
return true;
}
}
전체 코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.util.StringTokenizer;
public class Main {
static class TrieNode {
TrieNode[] children = new TrieNode[26];
}
static class Trie {
TrieNode root = new TrieNode();
// 1. 단어 삽입
public void insert(String word) {
TrieNode node = root;
for (int i = 0; i < word.length(); i++) {
int index = word.charAt(i) - 'a';
// 자식 노드가 없다면 새로 생성
if (node.children[index] == null) {
node.children[index] = new TrieNode();
}
// 다음 노드로 이동
node = node.children[index];
}
}
// 2. 접두사 탐색 (startsWith)
public boolean startsWith(String prefix) {
TrieNode node = root;
for (int i = 0; i < prefix.length(); i++) {
int index = prefix.charAt(i) - 'a';
// 접두사의 글자를 따라가다가 길이 끊기면 접두사가 아님
if (node.children[index] == null) {
return false;
}
node = node.children[index];
}
// 무사히 끝까지 도달했다면 접두사가 맞음
return true;
}
}
public static void main(String[] args) throws Exception {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
int N = Integer.parseInt(st.nextToken());
int M = Integer.parseInt(st.nextToken());
Trie trie = new Trie();
// N개의 문자열 트라이에 삽입
for (int i = 0; i < N; i++) {
trie.insert(br.readLine());
}
int count = 0;
// M개의 문자열이 접두사인지 확인
for (int i = 0; i < M; i++) {
if (trie.startsWith(br.readLine())) {
count++;
}
}
System.out.println(count);
}
}
◾ 마무리
이번 문제는 트라이(Trie)의 존재 이유인 접두사 검색(Prefix Search)을 연습할 수 있는 기본 문제였다.
댓글 0